# InfluxDB Troubleshooting
## Why??
Scrutiny has many features, but the relevant one to this conversation is the "S.M.A.R.T metric tracking for historical
trends". Basically Scrutiny not only shows you the current SMART values, but how they've changed over weeks, months (or
even years).
To efficiently handle that data at scale (and to make my life easier as a developer) I decided to add InfluxDB as a
dependency. It's a dedicated timeseries database, as opposed to the general purpose sqlite DB I used before. I also did
a bunch of testing and analysis before I made the change. With InfluxDB the memory footprint for Scrutiny (at idle) is ~
100mb, which is still fairly reasonable.
## Installation
InfluxDB is a required dependency for Scrutiny v0.4.0+.
https://docs.influxdata.com/influxdb/v2.2/install/
## Persistence
To ensure that all data is correctly stored, you must also persist the InfluxDB database directory
- If you're using the Official Scrutiny Omnibus image (`ghcr.io/analogj/scrutiny:master-omnibus`), the path is `/opt/scrutiny/influxdb`
- If you're deploying in Hub/Spoke mode with the InfluxDB maintained image (`influxdb:2.2`), the path is `/var/lib/influxdb2`
If you attempt to restart Scrutiny but you forgot to persist the InfluxDB directory, you will get an error message like follows:
```
scrutiny | time="2022-05-12T22:54:12Z" level=info msg="Trying to connect to scrutiny sqlite db: /opt/scrutiny/config/scrutiny.db\n"
scrutiny | time="2022-05-12T22:54:12Z" level=info msg="Successfully connected to scrutiny sqlite db: /opt/scrutiny/config/scrutiny.db\n"
scrutiny | ts=2022-05-12T22:54:12.240791Z lvl=info msg=Unauthorized log_id=0aQcVlOW000 error="authorization not found"
scrutiny | panic: unauthorized: unauthorized access
```
Unfortunately this may mean that your database is lost, and the previous Scrutiny data is unavailable.
You should fix the docker-compose/docker run command that you're using to ensure that your database folder is persisted correctly,
then delete the `web.influxdb.token` field in your `scrutiny.yaml` file, and then restart Scrutiny.
## First Start
The web/api service will trigger an InfluxDB onboarding process automatically when it first starts. After that, it will store the newly generated influxdb api token in the Scrutiny config file.
If this Credential is not correctly stored in the scrutiny config file, Scrutiny will fail to start (with an authentication error)
```
scrutiny | time="2022-05-12T22:52:55Z" level=info msg="Successfully connected to scrutiny sqlite db: /opt/scrutiny/config/scrutiny.db\n"
scrutiny | ts=2022-05-12T22:52:55.235753Z lvl=error msg="failed to onboard user admin" log_id=0aQcRnc0000 handler=onboard error="onboarding has already been completed" took=0.038ms
scrutiny | ts=2022-05-12T22:52:55.235816Z lvl=error msg="api error encountered" log_id=0aQcRnc0000 error="onboarding has already been completed"
scrutiny | panic: conflict: onboarding has already been completed
```
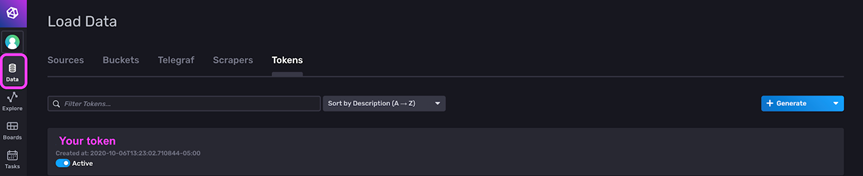
You can fix this issue by authenticating to the InfluxDB admin portal (the default credentials are username: `admin`, password: `password12345`),
then retrieving the API token, and writing it to your `scrutiny.yaml` config file under the `web.influxdb.token` field:
## Upgrading from v0.3.x to v0.4.x
When upgrading from v0.3.x to v0.4.x, some users have noticed problems such as:
```
2022/05/13 14:38:05 Loading configuration file: /opt/scrutiny/config/scrutiny.yaml
time="2022-05-13T14:38:05Z" level=info msg="Trying to connect to scrutiny sqlite db:"
time="2022-05-13T14:38:05Z" level=info msg="Successfully connected to scrutiny sqlite db:"
panic: a username and password is required for a setup
```
or
```
Start the scrutiny server
time="2022-06-11T10:35:04-04:00" level=info msg="Trying to connect to scrutiny sqlite db: \n"
time="2022-06-11T10:35:04-04:00" level=info msg="Successfully connected to scrutiny sqlite db: \n"
panic: failed to check influxdb setup status - parse "://:": missing protocol scheme
```
As discussed in [#248](https://github.com/AnalogJ/scrutiny/issues/248) and [#234](https://github.com/AnalogJ/scrutiny/issues/234),
this usually related to either:
- Upgrading from the LSIO Scrutiny image to the Official Scrutiny image, without removing LSIO specific environmental
variables
- remove the `SCRUTINY_WEB=true` and `SCRUTINY_COLLECTOR=true` environmental variables. They were used by the LSIO
image, but are unnecessary and cause issues with the official Scrutiny image.
- Change your volume mappings to `/opt/scrutiny` from `/scrutiny`
- Updated versions of the [LSIO Scrutiny images are broken](https://github.com/linuxserver/docker-scrutiny/issues/22),
as they have not installed InfluxDB which is a required dependency of Scrutiny v0.4.x
- You can revert to an earlier version of the LSIO image (`lscr.io/linuxserver/scrutiny:060ac7b8-ls34`), or just
change to the official Scrutiny image (`ghcr.io/analogj/scrutiny:master-omnibus`)
Here's a couple of confirmed working docker-compose files that you may want to look at:
- https://github.com/AnalogJ/scrutiny/blob/master/docker/example.hubspoke.docker-compose.yml
- https://github.com/AnalogJ/scrutiny/blob/master/docker/example.omnibus.docker-compose.yml
## Bring your own InfluxDB
> WARNING: Most users should not follow these steps. This is ONLY for users who have an EXISTING InfluxDB installation which contains data from multiple services.
> The Scrutiny Docker omnibus image includes an empty InfluxDB instance which it can configure.
> If you're deploying manually or via Hub/Spoke, you can just follow the installation instructions, Scrutiny knows how
> to run the first-time setup automatically.
The goal here is to create an InfluxDB API key with minimal permissions for use by Scrutiny.
- Create Scrutiny buckets (`metrics`, `metrics_weekly`, `metrics_monthly`, `metrics_yearly`) with placeholder config
- Create Downsampling tasks (`tsk-weekly-aggr`, `tsk-monthly-aggr`, `tsk-yearly-aggr`) with placeholder script.
- Create API token with restricted scope
- NOTE: Placeholder bucket & task configuration will be replaced automatically by Scrutiny during startup
The placeholder buckets and tasks need to be created before the API token can be created, as the resource ID's need to
exist for the scope restriction to work.
Scopes:
- `orgs`: read - required for scrutiny to find it's configured org_id
- `tasks`: scrutiny specific read/write access - Scrutiny only needs access to the downsampling tasks you created above
- `buckets`: scrutiny specific read/write access - Scrutiny only needs access to the buckets you created above
### Setup Environmental Variables
```bash
# replace the following values with correct values for your InfluxDB installation
export INFLUXDB_ADMIN_TOKEN=pCqRq7xxxxxx-FZgNLfstIs0w==
export INFLUXDB_ORG_ID=b2495xxxxx
export INFLUXDB_HOSTNAME=http://localhost:8086
# if you want to change the bucket name prefix below, you'll also need to update the setting in the scrutiny.yaml config file.
export INFLUXDB_SCRUTINY_BUCKET_BASENAME=metrics
```
### Create placeholder buckets
Click to expand!
```bash
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/buckets \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"name": "${INFLUXDB_SCRUTINY_BUCKET_BASENAME}",
"orgID": "${INFLUXDB_ORG_ID}",
"retentionRules": []
}
EOF
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/buckets \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"name": "${INFLUXDB_SCRUTINY_BUCKET_BASENAME}_weekly",
"orgID": "${INFLUXDB_ORG_ID}",
"retentionRules": []
}
EOF
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/buckets \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"name": "${INFLUXDB_SCRUTINY_BUCKET_BASENAME}_monthly",
"orgID": "${INFLUXDB_ORG_ID}",
"retentionRules": []
}
EOF
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/buckets \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"name": "${INFLUXDB_SCRUTINY_BUCKET_BASENAME}_yearly",
"orgID": "${INFLUXDB_ORG_ID}",
"retentionRules": []
}
EOF
```
### Create placeholder tasks
Click to expand!
```bash
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/tasks \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"orgID": "${INFLUXDB_ORG_ID}",
"flux": "option task = {name: \"tsk-weekly-aggr\", every: 1y} \nyield now()"
}
EOF
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/tasks \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"orgID": "${INFLUXDB_ORG_ID}",
"flux": "option task = {name: \"tsk-monthly-aggr\", every: 1y} \nyield now()"
}
EOF
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/tasks \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"orgID": "${INFLUXDB_ORG_ID}",
"flux": "option task = {name: \"tsk-yearly-aggr\", every: 1y} \nyield now()"
}
EOF
```
### Create InfluxDB API Token
Click to expand!
```bash
# replace these values with placeholder bucket and task ids from your InfluxDB installation.
export INFLUXDB_SCRUTINY_BASE_BUCKET_ID=1e0709xxxx
export INFLUXDB_SCRUTINY_WEEKLY_BUCKET_ID=1af03dexxxxx
export INFLUXDB_SCRUTINY_MONTHLY_BUCKET_ID=b3c59c7xxxxx
export INFLUXDB_SCRUTINY_YEARLY_BUCKET_ID=f381d8cxxxxx
export INFLUXDB_SCRUTINY_WEEKLY_TASK_ID=09a64ecxxxxx
export INFLUXDB_SCRUTINY_MONTHLY_TASK_ID=09a64xxxxx
export INFLUXDB_SCRUTINY_YEARLY_TASK_ID=09a64ecxxxxx
curl -sS -X POST ${INFLUXDB_HOSTNAME}/api/v2/authorizations \
-H "Content-Type: application/json" \
-H "Authorization: Token ${INFLUXDB_ADMIN_TOKEN}" \
--data-binary @- << EOF
{
"description": "scrutiny - restricted scope token",
"orgID": "${INFLUXDB_ORG_ID}",
"permissions": [
{
"action": "read",
"resource": {
"type": "orgs"
}
},
{
"action": "read",
"resource": {
"type": "tasks"
}
},
{
"action": "write",
"resource": {
"type": "tasks",
"id": "${INFLUXDB_SCRUTINY_WEEKLY_TASK_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "write",
"resource": {
"type": "tasks",
"id": "${INFLUXDB_SCRUTINY_MONTHLY_TASK_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "write",
"resource": {
"type": "tasks",
"id": "${INFLUXDB_SCRUTINY_YEARLY_TASK_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "read",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_BASE_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "write",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_BASE_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "read",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_WEEKLY_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "write",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_WEEKLY_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "read",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_MONTHLY_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "write",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_MONTHLY_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "read",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_YEARLY_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
},
{
"action": "write",
"resource": {
"type": "buckets",
"id": "${INFLUXDB_SCRUTINY_YEARLY_BUCKET_ID}",
"orgID": "${INFLUXDB_ORG_ID}"
}
}
]
}
EOF
```
### Save InfluxDB API Token
After running the Curl command above, you'll see a JSON response that looks like the following:
```json
{
"token": "ksVU2t5SkQwYkvIxxxxxxxYt2xUt0uRKSbSF1Po0UQ==",
"status": "active",
"description": "scrutiny - restricted scope token",
"orgID": "b2495586xxxx",
"org": "my-org",
"user": "admin",
"permissions": [
{
"action": "read",
"resource": {
"type": "orgs"
}
},
{
"action": "read",
"resource": {
"type": "tasks"
}
},
{
"action": "write",
"resource": {
"type": "tasks",
"id": "09a64exxxxx",
"orgID": "b24955860xxxxx",
"org": "my-org"
}
},
...
]
}
```
You must copy the token field from the JSON response, and save it in your `scrutiny.yaml` config file. After that's
done, you can start the Scrutiny server
## Customize InfluxDB Admin Username & Password
The full set of InfluxDB configuration options are available
in [code](https://github.com/AnalogJ/scrutiny/blob/master/webapp/backend/pkg/config/config.go?rgh-link-date=2023-01-19T16%3A23%3A40Z#L49-L51)
.
During first startup Scrutiny will connect to the unprotected InfluxDB server, start the setup process (via API) using a
username and password of `admin`:`password12345` and then create an API token of `scrutiny-default-admin-token`.
After that's complete, it will use the api token for all subsequent communication with InfluxDB.
You can configure the values for the Admin username, password and token using the config file, or env variables:
#### Config File Example
```yaml
web:
influxdb:
token: 'my-custom-token'
init_username: 'my-custom-username'
init_password: 'my-custom-password'
```
#### Environmental Variables Example
`SCRUTINY_WEB_INFLUXDB_TOKEN` , `SCRUTINY_WEB_INFLUXDB_INIT_USERNAME` and `SCRUTINY_WEB_INFLUXDB_INIT_PASSWORD`
It's safe to change the InfluxDB Admin username/password after setup has completed, only the API token is used for
subsequent communication with InfluxDB.